Vietnamese Image Captioning - VLSP for Health 2021
In this post, I want to talk about Vietnamese Image Captioning for Healthcare domains. The problem is important in the context of Covid-19 eppidemic so the Vietnamese Groups have established a competition about it. It is took place in VLSP 2021 Workshop, and I got the 3rd position on the private leaderboard of this challenge. Link to the challenge: https://vlsp.org.vn/vlsp2021/eval/vieCap4H
1. Abstract
This study presents our approach on the automatic Vietnamese image captioning for healthcare domains in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure \ref{fig:example}. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 in the vietCap4H dataset, and the score is ranked 3$^{rd}$ on the private leaderboard.
Here is some example of the dataset including an image and its caption


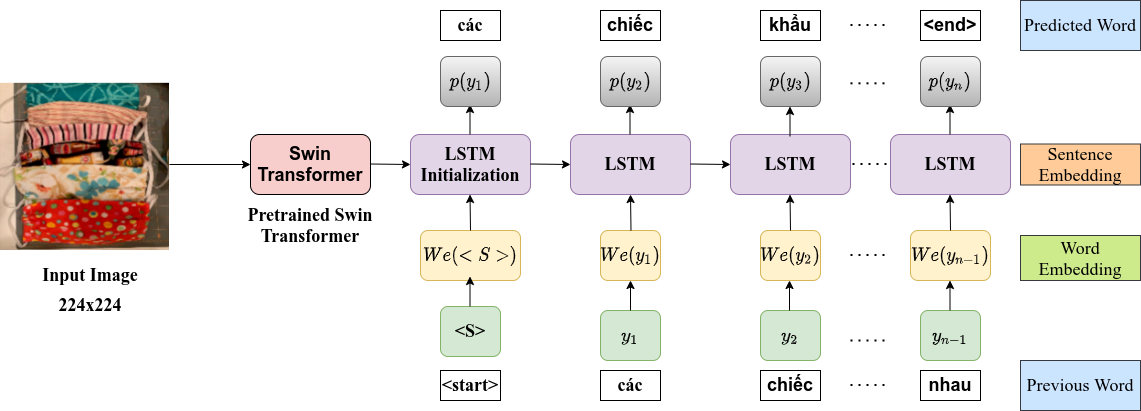
2. Model
Our model as shown here is an end-to-endfusion of a Swin Transformer encoder and bidirec-tional LSTM (biLSTM) decoder. The model takes in an image and outputs the corresponding caption.
3. Techniques
In this competition, I have used some techniques to improve the BLEU4 score, they are listed below:
3.1 Cross Validation
Cross Validation is a well-known technique that helps us choose the best model checkpoint among different folds. In this challenge, we train with 4 folds and choose the one that gives the best score on the leaderboard.
3.2 Noise Injection
In the field of image captioning, the accuracy ofprediction for the next character can be relativelyhigh if we can ensure that the previous sequenceis predicted correctly. However, if a character is mispredicted, then the prediction failure rate will gradually increase. To tackle the above issue, we use noise injection, which is done by randomly replacing ground truth characters with other characters during training, and new sentences will be called fake_labels. Then, using the modified sentences as the input for the decoder will force it to correctly predict the next character on the basis that the previous one was wrong.
3.3 Beam search
The algorithm is a best first search algorithm which iteratively considers the set of the k best sentences up to time (t) as candidates to generate sentences of size(t+ 1), and keep only the resulting bestkof them because this better approximates the probability of getting the global maximum. We tried beam search sizes from 1 to 10, and the best BLEU4 score achieved with a beam size 2.
4. Result
I got the 3rd position on the leaderboard, and some evolution of my attempt is shown here:

5. Application
Solving the problem leads to several practical applications such as virtual assistants for blind and visually impaired people, conducting visual content indexing and searching.
6. Code and Paper
Link code: Code
Link paper: Paper