In this post, I want to introduce a hot topic in Reinforcement Learning which is Instruction Navigation. Although Navigation can be tackled by using Supervised Learning, but using Reinforcement Learning help us learn without any human-labeled data.
Link paper: Paper
Link code: Code
The content is as following:
1. Introduction to Instruction Navigation
2. Principle
3. Methodology
4. Application
5. Reference
1. Introduction to Instruction NavigationNavigation problem is a familiar topic and it has been carried out many experiments in so many years. The problem is to make an agent move in an environment and achieve a predefined target. In general, this problem can be solved by Reinforcement Learning, the agent will receive an observation which contains several information such as image, depth, segmentation or sensor information, etc. Howerver, human want to make command for the agent through instruction, so the agent now has an additional information which is a text, or voice. The low-level instruction will be simple commands such as go straight, go left, go right, etc, but in practice, the instruction is more complex, it needs to consider other elements such as size, color, etc of the objects nearby. And that is the motivation of the Instruction Navigation problem.
The principle of Vision-Language problems is how to fuse multiple features together.
And with this problem, it composes of 3 components, (1) is to get image features, (2) is to get textual features, (3) is how to fuse these features together which is the most important part. In this paper, the fusion strategy they've used is concatenation and Hadarmard (element-wise) product. The final stage is the decision-making part, which employs a policy learning algorithm to make decision. A well-known but simple algorithm used in this situation is Asynchronous Actor Critic (A3C).
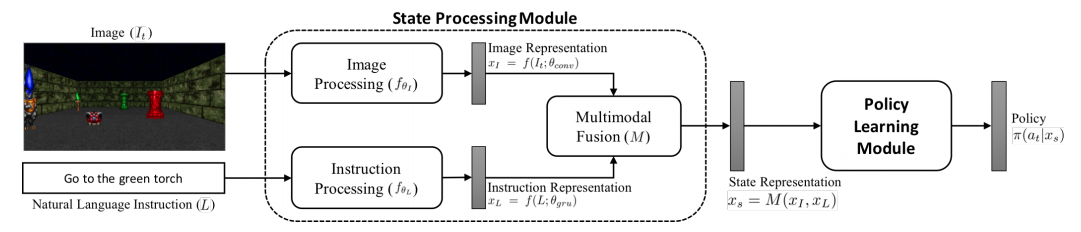
The methodology simply takes an image and an instruction as inputs. Noted that, with each episode, there is only one instruction, but the image changes continually.
3.1 Image Representation Module
In order to extract visual features, they employed a simple 3-layer CNN.
3.2 Text Representation Module
In terms of extracting textual features, first, they employed Word Embedding on the text input, then converted it to sentence embedding by using LSTM or GRU.
3.3 Attented Representation Module
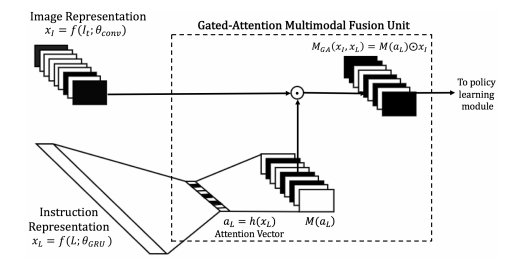
After getting a hold of 2 feature vectors, they use Hadardmard (element-wise) product to fuse the features together, and this is called Gated Attention.
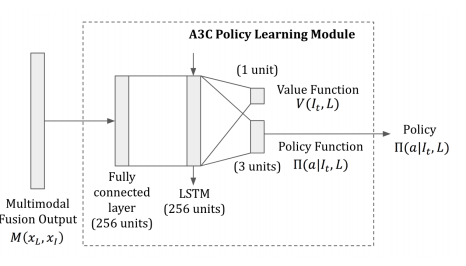
The policy learning will help the agent make decision which direction is going on. In this paper, the author use A3C, which is a well-known but simple reinforcement learning algorithm.
This algorithm can be applied to robotics, however, this stll have some limits such as only handling short, and simple instructions.
Paper
Code
(Tín Nguyễn)